Know Your Limits
"Man's got to know his limitations." — Dirty Harry
Your resources are limited. You only have so much time and money to do your work, including the time and money needed to keep your knowledge, skills, and tools up-to-date. You can only work so hard, so fast, so smart, and so long. Your tools are only so powerful. Your target machines are only so powerful. So you have to respect the limits of your resources.
How to respect those limits? Know yourself, know your people, know your budgets, and know your stuff. Especially, as a software engineer, know the space and time complexity of your data structures and algorithms, and the architecture and performance characteristics of your systems. Your job is to create an optimal marriage of software and systems.
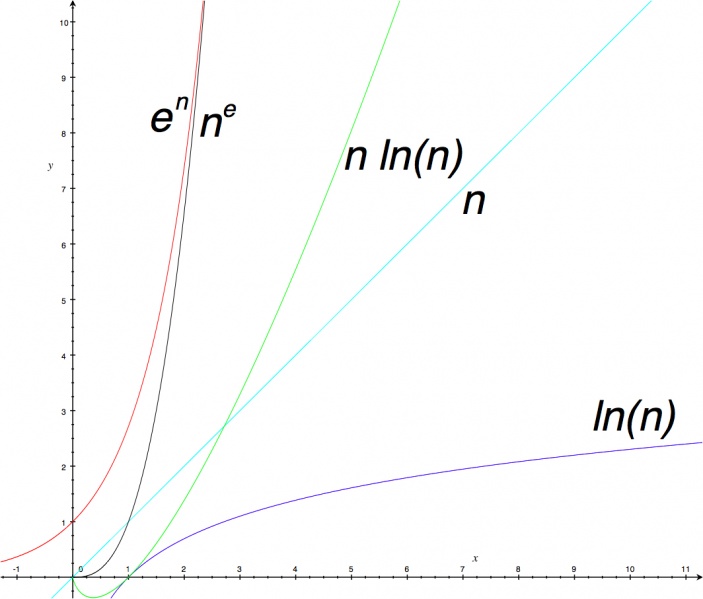
Space and time complexity are given as the function O(f(n)) which for n equal the size of the input is the asymptotic space or time required as n grows to infinity. Important complexity classes for f(n) include ln(n), n, n ln(n), ne, and en. As graphing these functions clearly shows, as n gets bigger O(ln(n)) is ever so much smaller than O(n) and O(n ln(n)), which are ever so much smaller than O(ne) and O(en). As Sean Parent puts it, for achievable n all complexity classes amount to near-constant, near-linear, or near-infinite.
| access time | capacity | |
|---|---|---|
| register | < 1 ns | 64 b |
| cache line | 64 B | |
| L1 cache | 1 ns | 64 KB |
| L2 cache | 4 ns | 8 MB |
| RAM | 20 ns | 32 GB |
| disk | 10 ms | 10 TB |
| LAN | 20 ms | > 1 PB |
| Internet | 100 ms | > 1 ZB |
Complexity analysis is in terms of an abstract machine, but software runs on real machines. Modern computer systems are organized as hierarchies of physical and virtual machines, including language runtimes, operating systems, CPUs, cache memory, random-access memory, disk drives, and networks. The first table shows the limits on random access time and storage capacity for a typical networked server.
Note that capacity and speed vary by several orders of magnitude. Caching and lookahead are used heavily at every level of our systems to hide this variation, but they only work when access is predictable. When cache misses are frequent the system will be thrashing. For example, to randomly inspect every byte on a hard drive could take 32 years. Even to randomly inspect every byte in RAM could take 11 minutes. Random access is not predictable. What is? That depends on the system, but re-accessing recently used items and accessing items sequentially are usually a win.
Algorithms and data structures vary in how effectively they use caches. For instance:
- Linear search makes good use of lookahead, but requires O(n) comparisons.
- Binary search of a sorted array requires only O(log(n)) comparisons.
- Search of a van Emde Boas tree is O(log(n)) and cache-oblivious.
| 8 | 50 | 90 | 40 |
|---|---|---|---|
| 64 | 180 | 150 | 70 |
| 512 | 1200 | 230 | 100 |
| 4096 | 17000 | 320 | 160 |
| linear | binary | vEB |
How to choose? In the last analysis, by measuring. The second table shows the time required to search arrays of 64-bit integers via these three methods. On my computer:
- Linear search is competitive for small arrays, but loses exponentially for larger arrays.
- van Emde Boas wins hands down, thanks to its predictable access pattern.
"You pays your money and you takes your choice." — Punch